Building Your Own Large Language Model (LLM): A Step-by-Step Guide
Large Language Models (LLMs), such as OpenAI’s GPT or Google’s BERT, have transformed the fields of natural language processing (NLP) and artificial intelligence. These models are built using deep learning architectures, typically transformers, and have proven to be effective in a variety of tasks, from text generation to translation. In this blog, we will take a deep dive into understanding LLMs, their internal structure, and how you can create your own LLM model.
1. What is a Large Language Model (LLM)?
LLMs are neural networks trained on massive amounts of textual data. They can predict the next word in a sequence, understand context, and generate human-like text. They are based on deep learning techniques, most notably transformer architectures. LLMs have billions of parameters, making them capable of understanding and generating complex human language.
Popular Examples of LLMs
- GPT-3 (OpenAI)
- BERT (Google)
- T5 (Google)
- ChatGPT (OpenAI)
2. API Access for Existing LLMs
If you’re interested in leveraging existing LLMs, many providers offer API access, allowing you to integrate these powerful models into your applications without building from scratch. Here’s how you can access some of the popular LLM APIs:
2.1. OpenAI GPT-4 API
- API Link: OpenAI API
- How to Use: OpenAI provides an API that allows you to send text inputs and receive model-generated outputs. You can access this API by signing up for an API key, which you can use in your Python code or other programming environments.
Example Usage in Python:
import openai
openai.api_key = 'your-api-key-here'
response = openai.Completion.create(
engine="text-davinci-003",
prompt="What is the capital of France?",
max_tokens=50
)
print(response.choices[0].text.strip())2.2. Hugging Face Transformers API
- API Link: Hugging Face API
- How to Use: Hugging Face provides a wide array of transformer models like GPT, BERT, T5, and many others. You can either use their hosted API or download pre-trained models.
2.3. Google Cloud NLP API
- API Link: Google Cloud NLP
- How to Use: Google Cloud’s NLP API provides access to powerful pre-trained models like BERT and T5. It’s often used for tasks like sentiment analysis, entity recognition, and text classification.
3. The Internal Structure of Large Language Models
Large Language Models are based on complex neural network architectures. The most common architecture used in LLMs is the Transformer. Let’s explore the key components:
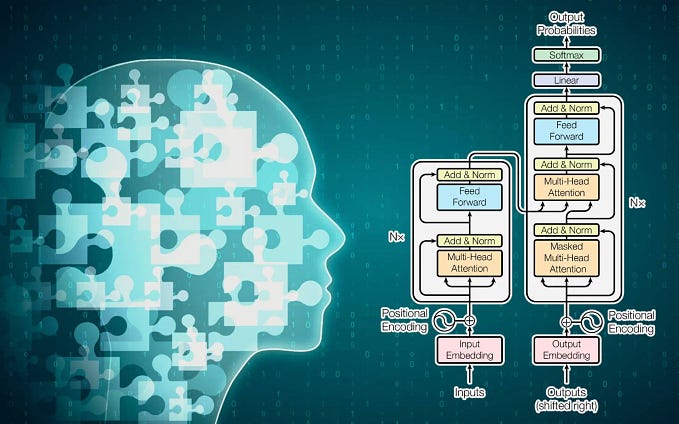
3.1. Transformer Architecture
Transformers are deep learning models designed to process sequential data, like text, but with the benefit of being highly parallelizable, which allows them to scale efficiently.
Key Components of a Transformer:
- Input Embeddings: Converts words or tokens into dense vectors that represent semantic information.
- Multi-Head Self-Attention: Allows the model to focus on different parts of the input sentence at the same time, helping it capture long-range dependencies in text.
- Feedforward Neural Networks: Applies transformation to the attention outputs, helping to add more non-linearity and learn more complex patterns.
- Layer Normalization: Stabilizes training by normalizing inputs to each layer.
- Positional Encoding: Provides information about the position of words in a sentence, which is essential since transformers do not inherently capture sequential order.
- Output Layer: A softmax layer is applied to generate the final output, which is a probability distribution over the next word or token in the sequence.
3.2. Neurons and Layers in LLMs
In LLMs, each layer contains a large number of neurons, with a typical architecture having several hundred layers and billions of parameters.
- GPT-3 (175 billion parameters): GPT-3 has 96 layers, 12,288 hidden units per layer, and 96 attention heads. This massive architecture allows the model to generate high-quality, coherent text.
- BERT (110 million to 340 million parameters): BERT has 12–24 layers, 768–1024 hidden units per layer, and 12–16 attention heads. BERT is pre-trained using a masked language model (MLM) approach, making it effective at understanding context.
3.3. Activation Functions
Activation functions introduce non-linearity into the network, allowing it to learn more complex patterns. In LLMs, the most commonly used activation functions are:
- ReLU (Rectified Linear Unit): f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x)
- Pros: Simple and efficient.
- Use Case: Commonly used in the feedforward layers of transformers.
2. GeLU (Gaussian Error Linear Unit):
- f(x)=0.5x(1+erf(x/2))f(x) = 0.5x(1 + \text{erf}(x/\sqrt{2}))f(x)=0.5x(1+erf(x/2))
- Pros: Smoother than ReLU and typically used in modern transformer architectures like GPT and BERT.
4. Steps to Build Your Own LLM Model
Now, let’s explore the steps to create your own LLM using transformer architecture.
4.1. Dataset Collection and Preprocessing
LLMs require large datasets for training. Popular datasets include:
- Common Crawl: A large-scale dataset of web pages.
- Wikipedia: Often used to train models for factual text generation.
- BooksCorpus: A collection of fiction books used for pre-training.
Steps:
- Tokenization: Break down the text into smaller chunks called tokens (words or sub-words).
- Text Preprocessing: Clean the text by removing special characters, normalizing case, and handling punctuation.
- Vocabulary Creation: Build a vocabulary of tokens that the model will use to understand and generate text.
4.2. Model Design (Transformer Architecture)
Using a framework like PyTorch or TensorFlow, you can design your own transformer model. Below is a simplified example of how you might define a basic transformer in PyTorch:
Transformer Model Code (PyTorch):
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleTransformer(nn.Module):
def __init__(self, vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward):
super(SimpleTransformer, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.transformer = nn.Transformer(d_model=d_model, nhead=nhead, num_encoder_layers=num_encoder_layers,
num_decoder_layers=num_decoder_layers, dim_feedforward=dim_feedforward)
self.fc = nn.Linear(d_model, vocab_size)
def forward(self, src, tgt):
src_emb = self.embedding(src)
tgt_emb = self.embedding(tgt)
output = self.transformer(src_emb, tgt_emb)
return self.fc(output)
# Hyperparameters
vocab_size = 50000 # Size of your vocabulary
d_model = 512 # Dimension of model layers
nhead = 8 # Number of attention heads
num_encoder_layers = 6 # Number of encoder layers
num_decoder_layers = 6 # Number of decoder layers
dim_feedforward = 2048 # Feedforward layer size
# Initialize and train model
model = SimpleTransformer(vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward)4.3. Training the Model
Training LLMs requires large computational resources (e.g., TPUs or multiple GPUs). The key steps in training include:
- Loss Function: Typically, cross-entropy loss is used for text generation.
- Optimizer: Adam optimizer is commonly used with learning rate schedulers to adjust the learning rate during training.
- Batching: Large datasets are divided into mini-batches to allow efficient training.
Example of Training Loop:
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(num_epochs):
for batch in train_loader:
src, tgt = batch
optimizer.zero_grad()
output = model(src, tgt)
loss = loss_fn(output.view(-1, vocab_size), tgt.view(-1))
loss.backward()
optimizer.step()4.4. Fine-Tuning
Once the model is pre-trained, it can be fine-tuned on specific tasks like text classification, summarization, or question-answering by training it on a smaller, task-specific dataset.
5. Deployment
After training your LLM, you can deploy it using cloud services like AWS, Google Cloud, or even via APIs like Hugging Face’s model hosting. These services allow you to scale your model and make it accessible to users.
6. Conclusion
Building an LLM from scratch involves understanding the inner workings of transformers, collecting and processing vast amounts of data, and utilizing the right hardware for training. While it’s resource-intensive, building your own model allows for customization and fine-tuning to specific needs. By leveraging frameworks like PyTorch and TensorFlow, and taking advantage of pre-trained models, you can accelerate the process.